Anthropic hat am 8. April 2026 Claude Managed Agents vorgestellt. Eine gehostete Agent-Runtime in der Anthropic-Cloud, inklusive Sandbox, Session-State, Tool-Ausführung und MCP-Anbindung. Du beschreibst einen Agenten über die API, Anthropic kümmert sich um alles was zwischen Modell-Call und Tool-Ergebnis passiert.
Für Entwickler und Agentur-Builder ist das die bisher dichteste Plattform, um Agent-Logik in eigene Produkte einzubauen, ohne selber Container, State-Layer, Credential-Vault und Recovery zu bauen. Für Einzelunternehmer und KMU ist das kein Tool zum Selber-Klicken, sondern das was hinter maßgeschneiderten KI-Lösungen steht, die jemand für dich baut.
Wie sich das zu den anderen Agent-Angeboten verhält
Für Endnutzer ohne technische Ambitionen ist das einfachste Anthropic-Angebot weiterhin Claude Cowork. Direkt in der Desktop-App, keine Config, keine API, keine Schwelle. Claude Code Routinen sind hauptsächlich für Entwickler gedacht, auch wenn motivierte Endnutzer mit etwas GitHub-Erfahrung einfache Workflows selbst aufsetzen können. ChatGPT Workspace Agents sind der klickbare Mittelweg, wenn dein Team ohnehin in ChatGPT arbeitet.
Claude Managed Agents sind eine Ebene tiefer. Keine Oberfläche für Nicht-Entwickler, kein Marketplace, keine vorgefertigten Vorlagen. Stattdessen eine API, mit der du Agent-Logik in eigene Apps, SaaS-Produkte oder interne Tools einbettest. Die Runtime steht, die Infrastruktur-Arbeit bleibt dir erspart.
Konkret heißt das: ein Agent für ein eigenes CRM, eine Ticket-Triage oder ein Research-Tool läuft nicht mehr auf einem Lambda plus Redis plus eigenem Sandbox-Container. Er läuft in der Claude Plattform, gesteuert über API-Calls aus deiner Anwendung.
Für Entwickler, die Claude ohnehin über die API nutzen, ist das der zweite Weg zum gleichen Modell. Die offizielle Abgrenzung:
| Messages API | Claude Managed Agents | |
|---|---|---|
| Was es ist | Direkter Modell-Zugriff über Prompts | Vorkonfigurierter Agent-Harness in gemanagter Infrastruktur |
| Wofür gedacht | Eigene Agent-Loops und feingranulare Kontrolle | Lang laufende Tasks und asynchrone Arbeit |
Wer selbst Orchestrierung, Tool-Ausführung und Recovery bauen will, bleibt bei der Messages API. Wer die Infrastruktur fertig haben will, nimmt Managed Agents.
Die vier Bausteine
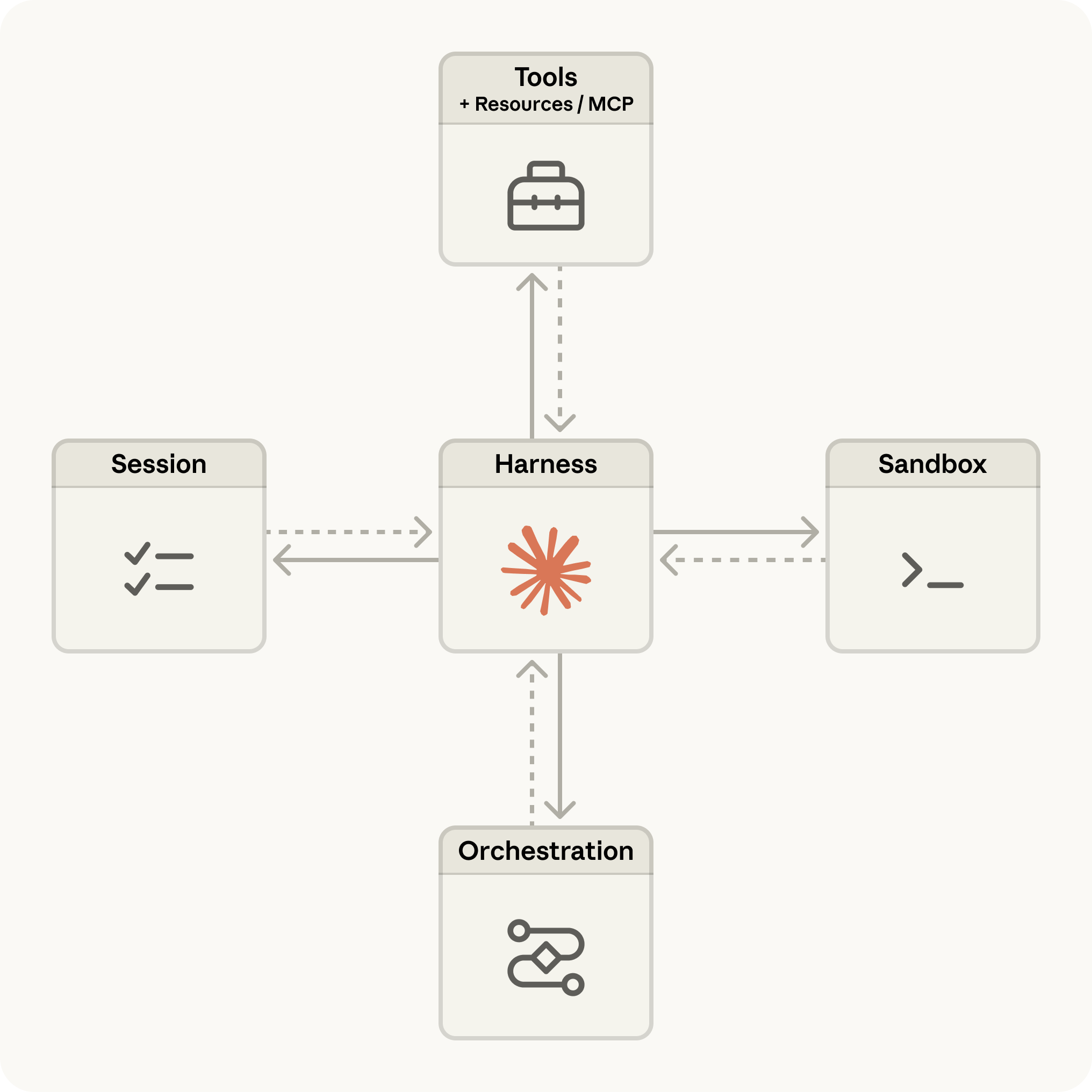
Quelle: Anthropic, aus dem offiziellen Launch-Artikel.
Die Plattform-Dokumentation beschreibt vier Konzepte, die jedes Projekt kennt:
- Agent: Modell, System-Prompt, Tools, MCP-Server und Skills. Wird einmal angelegt und per ID wiederverwendet.
- Environment: Ein Container-Template mit Python, Node.js, Go und definiertem Netzwerkzugriff. Auch einmal angelegt, mehrfach benutzt.
- Session: Eine laufende Agent-Instanz, die in einem Environment eine konkrete Aufgabe erledigt.
- Events: Die Nachrichten, die zwischen deiner App und dem Agenten fließen (user.message, agent.tool_use, session.status_idle, …).
Anthropic nennt das “decoupling the brain from the body” — das Modell und die Ausführungs-Umgebung sind getrennt, damit sich beides unabhängig weiterentwickeln kann.
Eingebaute Tools, plus MCP
Ein Managed Agent bekommt per Default Zugriff auf einen kuratierten Toolset:
- Bash: Shell-Kommandos im Container
- File operations: Read, write, edit, glob, grep
- Web search und Web fetch: Websuche und URL-Abrufe
- MCP-Server: Anbindung an externe Dienste wie Google Drive, Kalender, Slack, CRMs oder eigene Systeme
Das ist der entscheidende Unterschied zu Workspace Agents in ChatGPT: du bist nicht auf eine kuratierte Connector-Liste beschränkt. Alles, was über MCP verfügbar ist oder als MCP-Server selbst gebaut werden kann, lässt sich einbinden.
Ein erster Agent in Python
Der offizielle Quickstart zeigt den kompletten Ablauf. Als konkretes Beispiel für einen sinnvollen Business-Agent: ein Report-Agent, der eine CSV-Datei einliest, eine Auswertung in Python baut und einen kurzen Bericht als Markdown zurückgibt.
Voraussetzungen: API-Key, Python, pip install anthropic.
from anthropic import Anthropic
client = Anthropic()
# 1. Agent anlegen (einmal, dann per ID wiederverwenden)
agent = client.beta.agents.create(
name="Report-Agent",
model="claude-opus-4-7",
system=(
"Du bist ein Analyse-Assistent. "
"Du bekommst eine CSV-Datei mit Umsatzdaten. "
"Erstelle eine Python-Analyse der letzten 30 Tage, "
"fasse die drei wichtigsten Beobachtungen zusammen "
"und schreibe das Ergebnis als Markdown nach report.md."
),
tools=[{"type": "agent_toolset_20260401"}],
)
# 2. Environment anlegen (Container mit Python, Netzwerkzugriff)
environment = client.beta.environments.create(
name="report-env",
config={
"type": "cloud",
"networking": {"type": "unrestricted"},
},
)
# 3. Session starten
session = client.beta.sessions.create(
agent=agent.id,
environment_id=environment.id,
title="Monats-Report April",
)
# 4. Nachricht schicken und Stream lesen
with client.beta.sessions.events.stream(session.id) as stream:
client.beta.sessions.events.send(
session.id,
events=[{
"type": "user.message",
"content": [{"type": "text", "text": "Hier ist die Datei sales_april.csv. Bitte analysieren."}],
}],
)
for event in stream:
if event.type == "agent.message":
for block in event.content:
print(block.text, end="")
elif event.type == "agent.tool_use":
print(f"\n[Nutzt Tool: {event.name}]")
elif event.type == "session.status_idle":
print("\nFertig.")
break
Im Terminal sieht das dann ungefähr so aus:
Ich analysiere sales_april.csv und baue einen Monatsbericht.
[Nutzt Tool: read]
[Nutzt Tool: write]
[Nutzt Tool: bash]
Das Analyse-Skript ist durchgelaufen. Ich prüfe den Output.
[Nutzt Tool: bash]
Der Bericht ist in report.md gespeichert. Die drei wichtigsten Beobachtungen:
Umsatz plus 8 Prozent gegenüber März, Top-Kunde A macht 34 Prozent des Monatsumsatzes
aus, Kategorie "Services" wächst überproportional.
Fertig.
Was dabei passiert: der Agent liest die CSV mit read, schreibt ein Python-Analyse-Skript mit write, führt es mit bash aus, prüft das Ergebnis und legt den Markdown-Bericht ab. Du siehst im Stream jeden einzelnen Tool-Call und kannst ihn mitlesen oder mit einem neuen user.message-Event mittendrin umsteuern.
Der Code funktioniert mit dem Quickstart-Setup ohne weitere Pfade. Für Produktion würdest du Agent-ID und Environment-ID außerhalb speichern und in jedem Request wiederverwenden.
Wichtiger Detail: Alle Requests brauchen den Header anthropic-beta: managed-agents-2026-04-01. Das SDK setzt ihn automatisch, bei direktem cURL muss er gesetzt werden.
Was das kostet
Das Preismodell aus dem Launch-Artikel:
- Standard-Token-Raten für die Modellaufrufe (keine Änderung zur Messages API)
- Zusätzlich 0,08 USD pro Session-Stunde für die aktive Runtime
Das heißt: eine Session, die 15 Minuten arbeitet, kostet 2 Cent Runtime plus die Modell-Token für das was der Agent wirklich macht. Für einen Report-Agent, der ein paar Minuten läuft und mittlere Kontexte verarbeitet, landest du bei einstelligen Cent-Beträgen pro Durchlauf.
Rate Limits auf Organization-Ebene: 60 Create-Requests pro Minute, 600 Read-Requests pro Minute. Reicht für alle Szenarien außer industriellem Dauerfeuer.
Wer das heute schon produktiv nutzt
Anthropic nennt im Launch-Post die Early Adopters. Relevant ist nicht die Namensliste, sondern was daraus ablesbar ist:
- Notion hat Agenten direkt ins eigene Workspace integriert, sodass Teams Arbeit an Claude delegieren können, ohne Notion zu verlassen
- Rakuten hat den ersten produktiven Agenten in einer Woche ausgerollt
- Asana nutzt Managed Agents als Fundament für die Asana AI Teammates
- Sentry hat die Integration in Wochen statt Monaten durchgeschoben
Der gemeinsame Nenner: Firmen, die vorher einen eigenen Backend-Stack für Agents bauen wollten, haben ihn nicht gebaut und stattdessen Managed Agents genutzt. Das ist der Pitch in einem Satz.
Was Managed Agents dir abnehmen
Das Spannende an der Runtime ist weniger das, was du schreibst, als das was du nicht mehr schreiben musst. Managed Agents liefern ab:
- Isolierte Sandbox-Container: Der Agent bekommt eine Cloud-Umgebung, in der er sicher Code ausführen, Dateien bearbeiten und Tools aufrufen kann. Ohne eigenes Docker-Setup, ohne Kubernetes-Cluster
- Session-State: Gespräche, Dateien und Zwischenergebnisse bleiben über stunden- oder tagelange Aufgaben erhalten. Der Persistenz-Layer ist gebaut
- Agent-Loop: Die Entscheidung, wann Claude welches Tool aufruft, wann er ans Modell zurückgibt und wann er fertig ist, läuft in der Anthropic-Runtime. Der Orchestrator ist da
- Tool-Registry: Bash, File Operations, Web Search und Web Fetch sind eingebaut. MCP-Server hängst du einfach ran
- Streaming-Events: Jeder Schritt des Agenten kommt als Event-Stream zurück. Du kannst in Echtzeit mitlesen oder den Agenten mittendrin umlenken
- Performance-Optimierungen: Prompt-Caching, Context-Compaction und andere Tuning-Schritte passieren automatisch im Harness
Das sind alles Themen, die vor April 2026 zu einem eigenen Backend-Stack gehörten. Jetzt ist die Hürde, einen Agenten sauber in Produktion zu bringen, deutlich niedriger.
Was du damit bauen kannst
Ein paar Szenarien, die sich mit Managed Agents sauber abbilden lassen:
- Support-Agent: Liest Kunden-Tickets, holt relevante Dokumente über MCP aus deiner Wissensbasis, schreibt Antwortentwürfe zur Freigabe
- Research-Agent: Sucht via Web Search nach Branchen-News, bewertet sie gegen deine Interessen und baut ein tägliches Briefing
- Daten-Analyse-Agent: Bekommt CSV- oder DB-Exports, baut Python-Skripte zur Auswertung, produziert Charts und Markdown-Reports (das Code-Beispiel oben)
- Lead-Qualifizierung: Liest neue Formular-Anfragen, recherchiert Firma und Ansprechpartner im Web, schlägt einen Qualifizierungs-Score vor
- Dokumenten-Extraktion: Bekommt PDFs, extrahiert strukturierte Felder, validiert gegen Schemata, gibt sauberes JSON zurück
- Multi-Agent-Pipeline: Ein Haupt-Agent orchestriert spezialisierte Sub-Agents für parallele Recherche oder Bearbeitung (Research Preview)
Alle diese Szenarien wären vor der Managed-Agents-Runtime ein mehrwöchiges Backend-Projekt. Heute schrumpft der technische Kern auf Stunden bis Tage. Der Rest, also Feintuning für deinen Use Case, saubere Anbindung an deine Systeme und verlässlicher Betrieb, bleibt Entwickler-Arbeit. Aber das Fundament steht.
Neu seit 23. April: Memory über Sessions hinweg
Anthropic hat nur zwei Wochen nach dem Launch eine Memory-Funktion in Public Beta nachgezogen. Bisher war Session-State pro Session. Mit Memory bleibt Wissen auch über Sessions hinweg erhalten.
Technisch liegt die Memory als Dateisystem vor, auf das der Agent über seine bestehenden File-Operations und Bash-Tools zugreift. Dazu kommen Enterprise-Features: gescopte Berechtigungen, Audit-Logs, geteilte Memory-Stores mit pro-User- oder org-weitem Zugriff, versionierte Rollbacks und Content-Redaction.
Für den Praxis-Effekt nennt Anthropic Rakuten mit 97% weniger Fehlern im ersten Durchgang und Wisedocs mit 30% schnellerer Verifikation. Für eigene Use Cases heißt das: ein Support-Agent, der seine Entscheidungen aus vergangenen Tickets lernt. Ein Research-Agent, der weiß was er in den letzten Wochen schon recherchiert hat. Ein Analyse-Agent, der Firmen-spezifische Konventionen behält.
Memory ist optional. Wer sie nicht aktiviert, arbeitet weiter mit reinen Session-States wie im Launch-Modell.
Für wen sich das wirklich lohnt
Klar eindeutig für drei Profile:
SaaS-Builder und Agenturen. Du baust ein Produkt, in dem ein Agent eine konkrete Aufgabe übernimmt. Ticket-Triage, Dokumenten-Extraktion, Research, Code-Generierung. Statt eigene Container, Auth, State und Recovery zu bauen, nutzt du die Runtime. Schneller zum Prototyp, schneller in Produktion.
Technische Einzelunternehmer. Du willst einen Agenten in ein eigenes Tool einbauen, hast aber keinen Backend-Appetit. Python oder Node reicht, die Infrastruktur bleibt weg.
Unternehmen, die interne Tools bauen. Onboarding-Assistent, Support-Agent, Analyse-Agent für Daten, die nicht in der Standard-CRM stehen. Statt ein eigenes MLOps-Setup aufzubauen, läuft es über API-Calls aus der bestehenden App.
Für wen das nichts ist
Wenn du als Einzelunternehmer oder kleiner Betrieb einfach nur automatisieren willst, dass Montag morgens dein Wochenreport fertig ist, ist Managed Agents der falsche Einstieg. Der richtige Weg sind dann ChatGPT Workspace Agents oder Claude Code Routinen.
Managed Agents sind eine Infrastruktur-Schicht. Du brauchst etwas, das diese Schicht nutzt. Das kann deine eigene App sein, oder jemand der dir ein Tool auf dieser Basis baut.
Weiterführende Ressourcen
- Anthropic-Blog: Claude Managed Agents: get to production 10x faster
- Anthropic-Blog: Claude Managed Agents Memory
- Anthropic Engineering: Scaling Managed Agents
- Plattform-Docs: Claude Managed Agents Overview
- Quickstart mit Code-Beispielen in Python, TypeScript, Go, Java, C#, Ruby, PHP
- Mein Artikel zu ChatGPT Workspace Agents für KMU
- Mein Artikel zu Routinen in Claude Code
Nächster Schritt
Wenn du Managed Agents selbst ausprobieren willst, reicht ein Anthropic-Account, ein API-Key und das Code-Beispiel oben, um in weniger als einer Stunde einen ersten Agenten durchlaufen zu sehen. Für den Einstieg ist das der direkteste Weg.
Wenn du im Anschluss überlegst, wie du aus dem Prototyp ein Produkt machst, das im Alltag tragfähig ist, sprich mich an. Ich helfe beim Zuschnitt auf den Use Case, bei der Integration in bestehende Systeme und beim Betrieb.